摘要:梳理知识图谱构建通用思路,以及法律行业知识图谱构建的特色及问题。
名词解释
本体(Ontology)
概念:从客观世界中抽象出来的一个概念模型,表达领域内共同认可的概念、属性和概念间的关系。
作用:在知识图谱当中,本体是知识图谱的抽象表达,描述知识图谱的上层模式,反映的是常识或相对恒定的知识,不具备情报价值,被称为知识图谱的模式层。
举例:如”原告”是民事诉讼领域的一个概念,原告同时具有一些相关概念,例如“诉讼请求”。
实例(instances)
概念:客观世界当中与本体对应的,具体的存在、属性或关系。
作用:实例的抽取和利用是知识图谱获得情报价值的关键。知识库的形成,依赖本体的实例化,实例构成了知识图谱的数据层。
举例:例如“张三”在某个民事诉讼案件当中处于原告地位,“张三”就是本体“原告”的一个实例。
实体(Entity)
概念:简单理解就是本体+实例,是本体、实例及关系的整合。
举例:比如 “原告”是本体中的一个概念 ,概念中也规定了相关属性比如“诉讼请求”,“张三”是一个具体案件当中的原告,叫做实例,所以张三也有诉讼请求,张三以及体现张三的本体概念“原告”以及相关属性,叫做一个实体。
知识图谱行业现状
知识图谱行业现状的分析,从知识图谱的分类与典型应用、知识图谱的构建模式两个部分进行切入。目的是了解行业技术方案现状、厘清法律知识图谱的定位和可能参考的构建路径。
知识图谱的分类与典型应用
知识图谱可以分为开放知识图谱(又被称为:通用知识图谱,generic knowledge graph)和垂直领域知识图谱(又被称为:行业知识图谱, domain knowledge graph),其中开放知识图谱包含几乎所有领域的重要的概念、实体及其之间的关系,强调知识的覆盖广度;领域知识图谱则是基于某一个或若干个特定领域所构建的知识库,强调知识的准确程度。
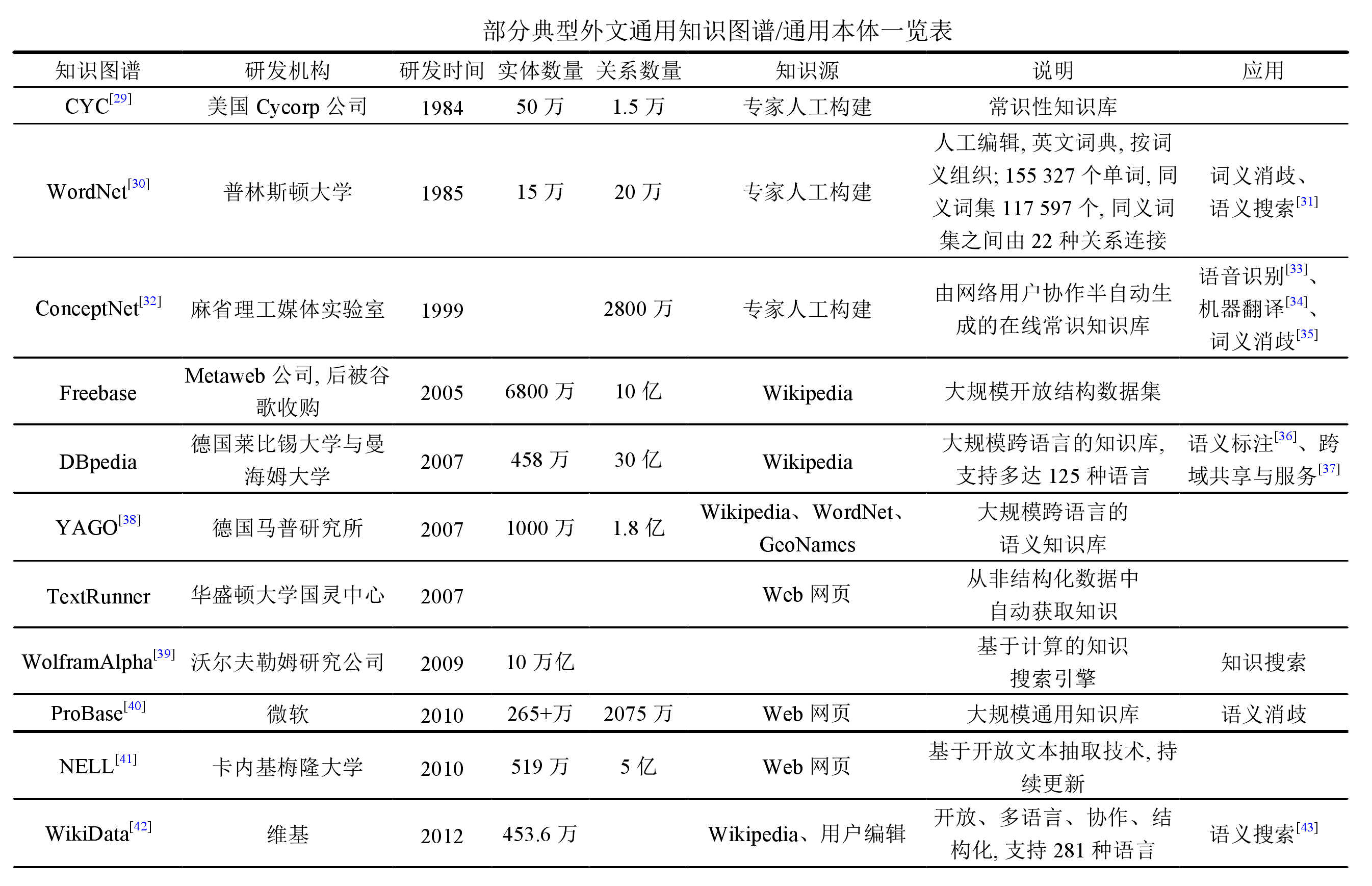
以下是搜集整理的典型知识图谱简介,可重点关注:图谱名称、实体数量、关系数量、知识源字段等信息,这是对知识图谱进行评价分析的常用维度,在构建法律行业知识图谱时,同样是关注的焦点。
开放知识图谱 (通用知识图谱)
- 开放知识图谱,也被称为通用知识图谱,国内部分典型案例如下
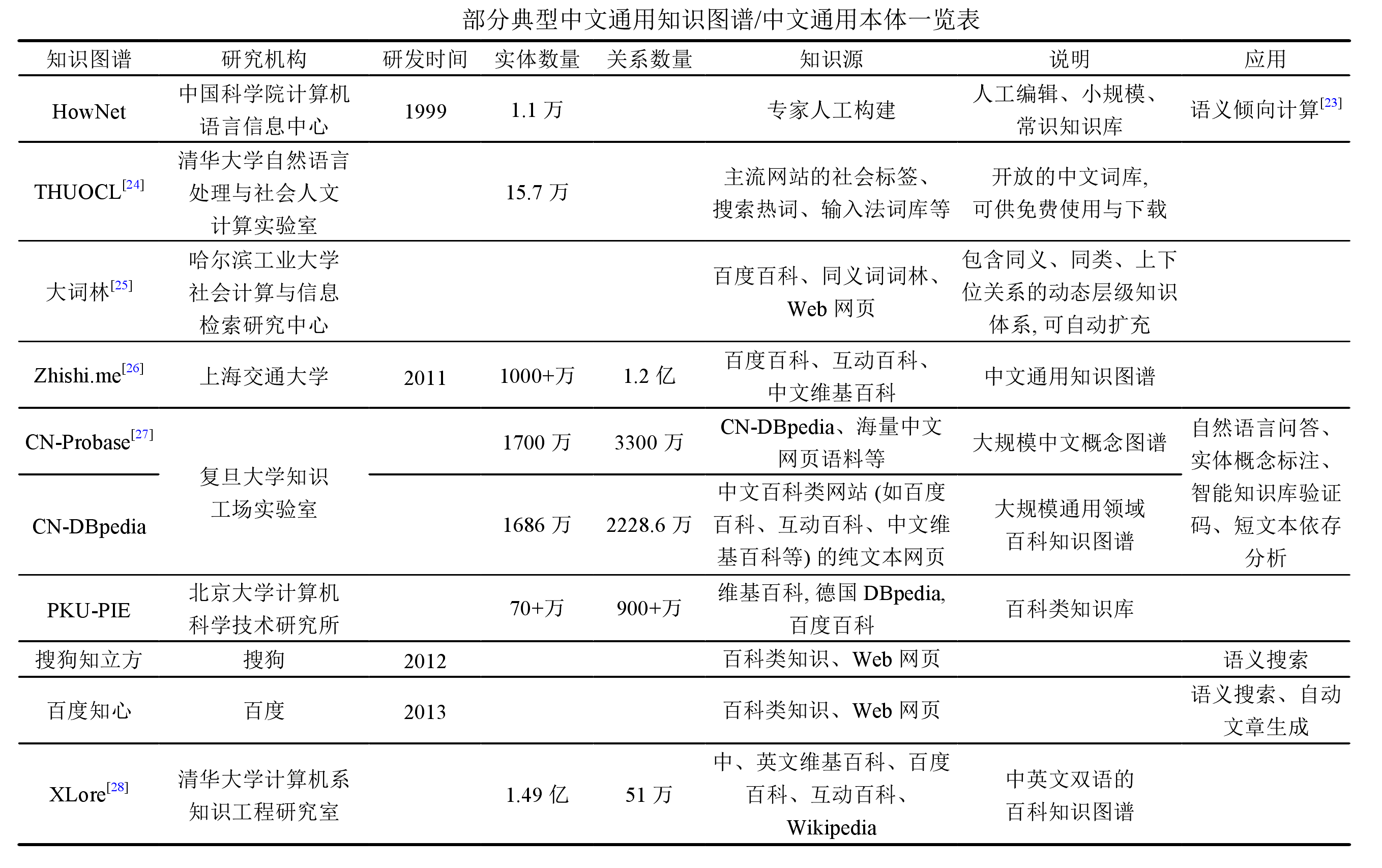
- 国外部分典型通用知识图谱
垂直领域知识图谱 (行业知识图谱)
- 垂直领域知识图谱,也被称为行业知识图,国内典型垂直领域知识图谱应用案例

两种图谱的比较
垂直领域本身具备知识图谱的所有特点,也应该吸收通用知识图谱的各种技术来促进自身的发展。
但是应当注意:由于垂直领域本身的特点,与开放(通用)知识图谱相比,在知识特点、知识来源、应用领域、受众方面都有较大不同。特别是在构建方法上,目前尚无统一成熟的构建流程,在知识获取、知识融合等关键技术领域仍处在探索阶段。

知识图谱的构建模式
一般认为,知识图谱的构建方法有三种: 自底向上、自顶向下和二者混合的方法。前两者的主要区别是:“本体构建” 与 “实例抽取” 的先后顺序不同,具体分析如下:
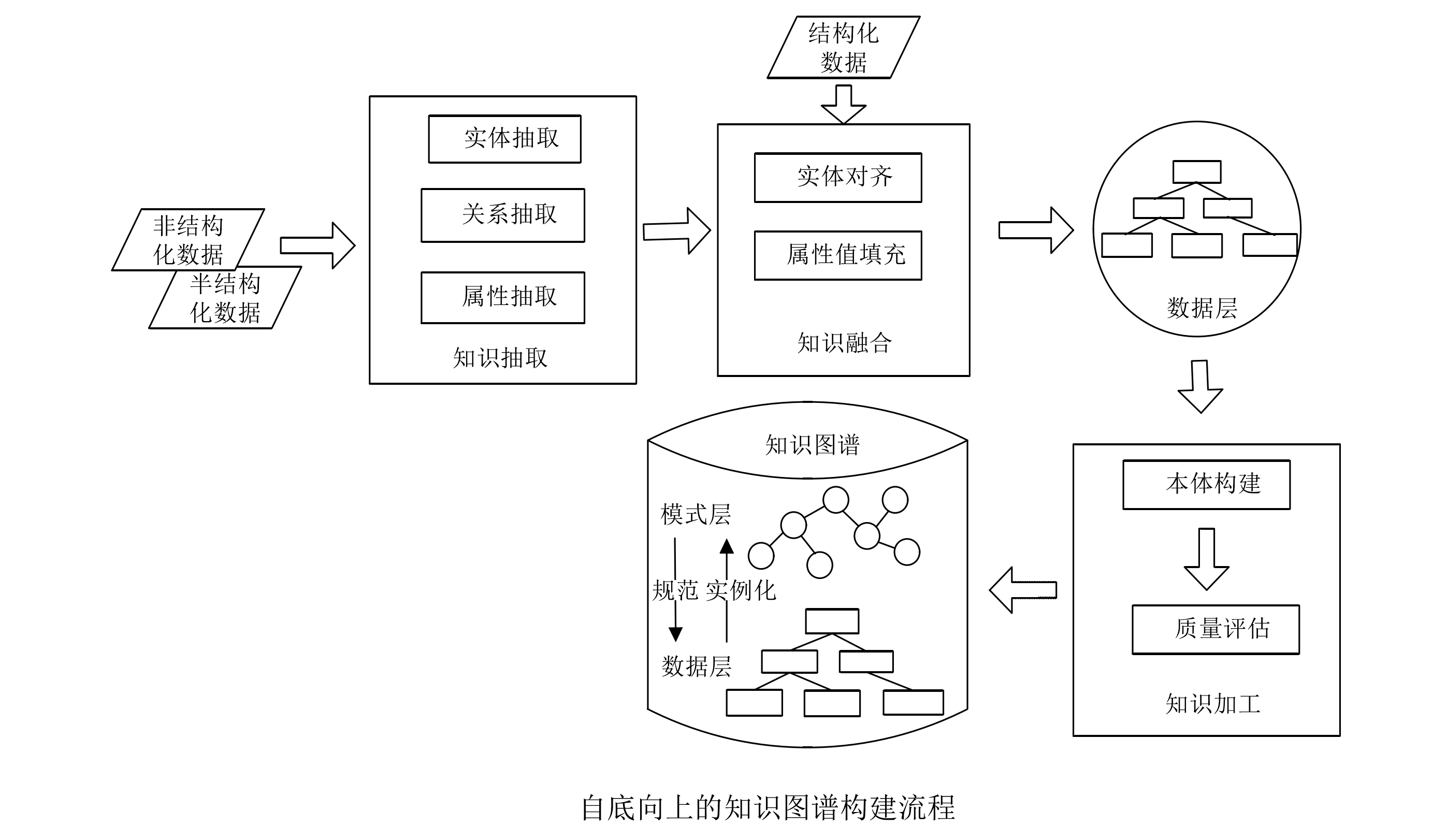
自底向上的构建模式
构建方法:step 1:实例抽取。 首先从一些非结构化数据、半结构化数据源中抽取实例、关系等,将其加入到知识库中形成数据层; step 2:本体构建。 对已经处理好的数据层进行概念抽象,最后形成模式层。
应用场景:适用于数据量较大的知识图谱的构建,如百科类的 DBpedia、zhishi.me 和语言学类的 WordNet、大词林等,主要应用于语义搜索, 强调知识的广度,对知识的准确度要求不高。
主要劣势:较难构建规范的本体层、准确性不高。
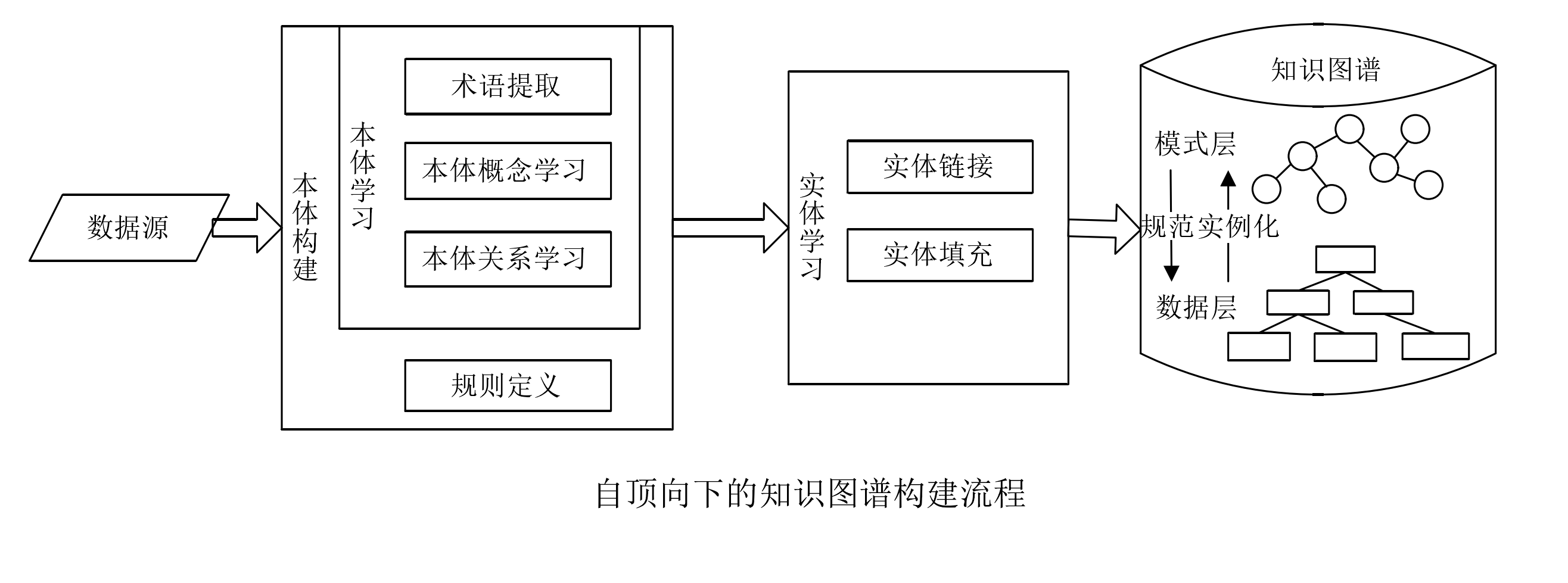
自顶向下的构建模式
构建方法:step 1:本体构建。从最顶层的概念开始构建顶层本体, 然后细化概念和关系, 形成结构良好的概念层次树,过程中需要利用一些数据源提取本体, 即本体学习;step 2:实例抽取。将抽取得到的实例、关系匹配填充到所构建的模式层本体中,形成知识图谱的数据层。
应用场景:面向特定领域, 能够进行知识推理,实现辅助分析及决策支持等功能, 如中医医案知识图谱等。行业知识图谱对专业性与准确度的要求高, 这也要求其必须有严格的本体层模式。
主要劣势:人工依赖性强、本体更新受限专业人员能力,一般适用于数据量小的知识图谱构建。
混合模式
构建方法:step 1:初始实例抽取。对数据进行初步实例抽取;step 2:本体构建。根据抽取结果,对新到的知识和数据进行归纳总结,辅助本体构建和迭代;step 3:实例抽取。基于更新后的模式层进行新一轮的实例抽取。
应用场景:如百度知识图谱, 就是利用内外部以及用户数据采用混合方法构建所得
主要问题:初始实例抽取的依据不明,可能需要有一定基础或前置处理经验。
小结
一般认为:三种知识图谱构建方法, 自顶向下法较好体现概念间层次, 但人工依赖性强、模式层更新受限,仅适用于数据量小的知识图谱构建;自底向上法更新快、支持大数据量的知识图谱构建,但知识噪音大、准确性不高;混合方法灵活性强,但模式层构建难度大。
法律知识图谱的构建思路
法律行业知识图谱具有强烈的领域特色,在知识图谱的构建中,除了考虑技术路径可行性,也需要对行业需求和关注点进行分析。
法律思维与通用大数据思维的冲突
演绎思维冲突
法律是一种社会规范,有不同于自然科学的应然追求。法律的施行,是在三段论的逻辑框架下进行的演绎。与之相反,通用大数据认识论则强调经验主义的归纳。
因果思维冲突
在法律思维和法律方法中因果性占据着十分重要的地位。这与经验主义的通用大数据认识论强调的“去因果分析”不相兼容。
说理思维冲突
司法过程通常被视为一种重要的凝结共识机制。任何决定都必须在证明、推理与审议的基础上作出。 因此,法律思维强调解释说理。当前,在通用大数据中使用较为普遍的深度学习算法,尤其是神经网络算法就因为可解释性的不足而持续面临法律人的质疑。
从“数据驱动”到“知识+数据驱动”
上述行业知识图谱建设经验,以及法律行业特有的思维冲突分析对我们在探讨知识图谱的构建方法时,具有路径上的指引:
依据法学理论,科学确定法律领域本体,是知识图谱构建的前置环节
首先,作为典型的行业知识图谱,需要通过预先设定领域本体,来明确挖掘分析的边界;其次为了解决可解释性的担忧,需要引入法学理论参与到本体层的构建当中,例如针对刑事犯罪的“四要件”、“三阶层”理论,针对民事案件的“请求权基础”理论,来明确本体构建的结构和各部分的关系。另外,法律领域本体的构建需要与业务场景需求进行关联,面向不同法律材料形成不同的子领域本体集。
依据法学知识,精细划分抽取的数据集,是进行实例抽取的必要准备
法律数据材料纷繁复杂,类型多样、价值高低不一,输入粗劣的数据将不可避免地产生错误的输出,为避免垃圾进,垃圾出(英语:Garbage in, garbage out)就需要依据法律专业知识对法律素材数据进行分类、鉴别。例如在利用裁判文书时,需要考虑法律变迁时间节点、案由、地区等因素。
依据法学知识,细致定义实例抽取规则,是数据质量和准确率的保障
实例抽取规则的定义,同样需要结合法律专业知识。以裁判文书为例,相同的法律概念可能在文本当中多次出现,但对概念的认定可能存在前后矛盾,比如在刑事案件中对被告人是否构成自首,检察机关、被告人、法院的意见可能是截然相反的,依据裁判文书的行文思路,写在裁判分析过程段(以“本院认为……”开头)才是最终认定结论。特定要素的提取,只有限定在特定的段落才能保证准确性。
知识图谱的运用环节,也应当将法学理论作为分析结果的解释性框架
在对知识图谱输出结果进行解释的环节,需要对推理依据和过程进行显性展示,例如对于相似案件的推荐功能,需要明晰判断类案的依据,例如同时满足包含特定法律本体要素,且本体之间的关系是一致的。通过在本体构建时确定的解释性框架,对实际个案进行解释。
参考文献:
[1] 黄恒琪, 于娟, 廖晓, 等. 知识图谱研究综述[J/OL]. 计算机系统应用, 2019, 28(6): 1-12. DOI:10.15888/j.cnki.csa.006915.
[2] 陈雅茜, 邢雪枫. 基于本体建模的动态知识图谱构建技术研究[J]. 西南民族大学学报(自然科学版), 2021, 47(3): 310-316.
[3] 王禄生. 论法律大数据“领域理论”的构建[J/OL]. 中国法学, 2020(2): 256-279. DOI:10.14111/j.cnki.zgfx.2020.02.014.